File System to Veeva Vault | Implementation Template
File System to Veeva Vault
To create documents and object records in vault using both metadata from CSV files on the local file system. In the case of documents, files and renditions can be uploaded from the local file system as well.
This template contains following mule application files:
1. create-documents-using-metadata-from-file.xml :–
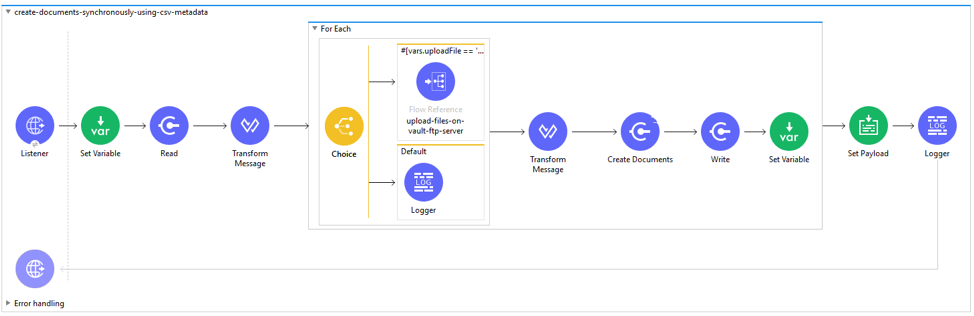
The flow (create-documents-synchronously-using-csv-metadata) reads CSV document metadata from local file (create-documents-data.csv) and passes batch of 500 records to upload respective document file on Vault FTP server through sub-flow (upload-files-on-vault-ftp-server) and create documents on Vault with document file attached to it. The status of documents created are recorded in a file on the local filesystem through the Write operation.
Uploading Document Files
The flag UploadFileneed to pass as query parameter (while triggering the flow) to controls whether document file attachments are uploaded in addition to metadata. Set this flag to “true” to include file attachments, however if only metadata is required with no document attachments pass the flag “UploadFile=false” instead.
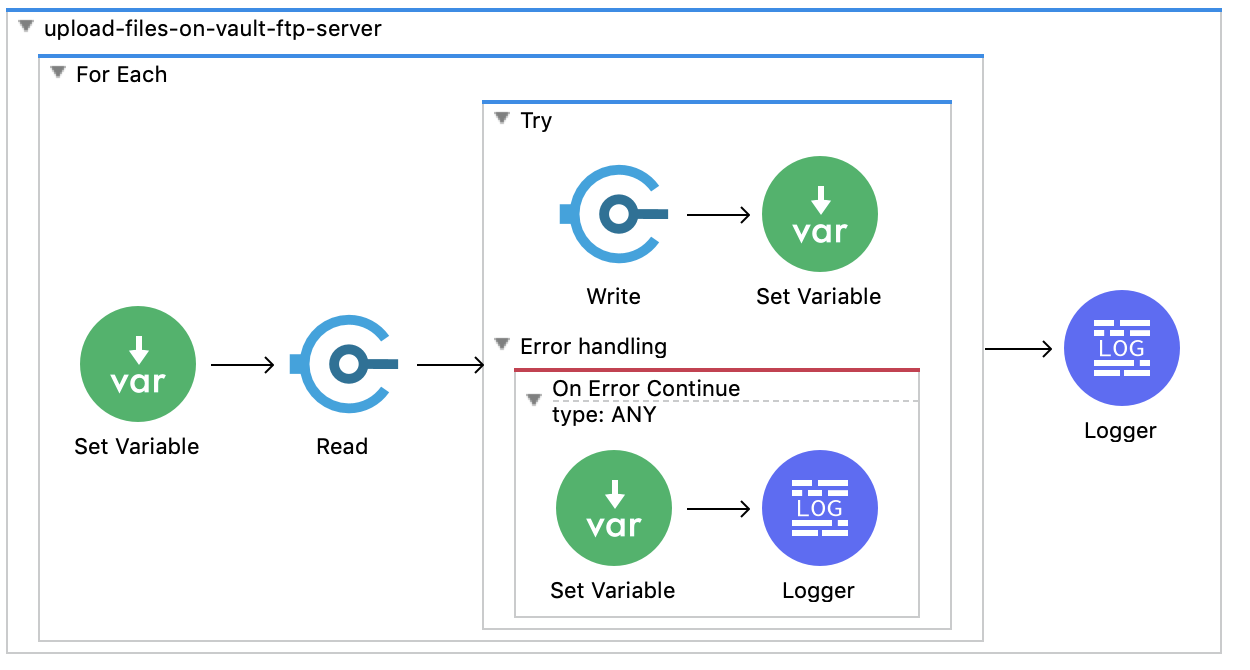
The above flow uploads document files from a local file system to the Vault FTP Staging server so they can later be imported into Vault within the above flow create-documents-using-metadata-from-file. It’s worth noting that this use case will only work when deployed in an on-premises environment and not within instead on Cloudhub.
Should you wish to upload files from a different source than a local file system the file Read operation will need to be replaced with a read file operation appropriate to that source. For instance, if you wanted to use an on cloud file store such as AWS S3, you will have to replace File Read operation in the flow upload-files-on-vault-ftp-server with the same operation within the MuleSoft AWS S3 connector.
The flow (independent-upload-files-on-vault-ftp-server) can be used in Migration use case where high volume of document files need to pre-load on Vault FTP server prior to document creation.
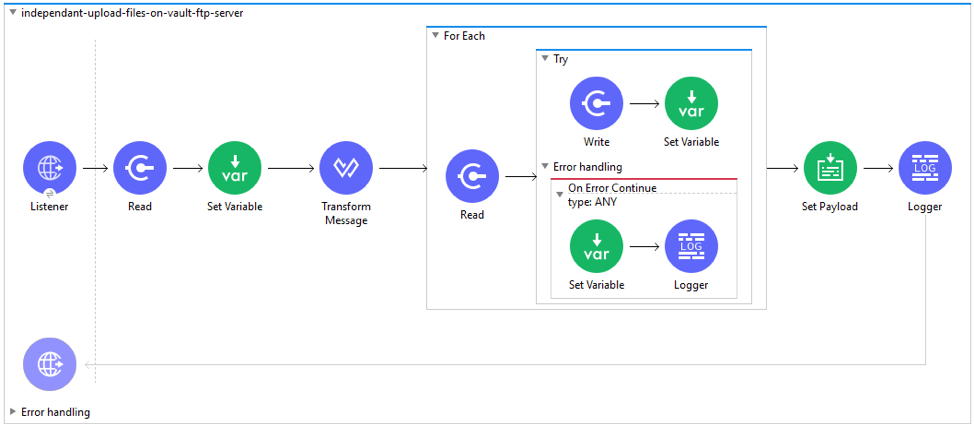
As with the independent-upload-files-on-vault-ftp-server flow, it’s worth noting that this use case will only work when deployed in an on-premises environment and not within instead on Cloudhub.
Should you wish to upload files from a cloud file store such as AWS S3, you will have to replace File Read operation in the flow independant-upload-files-on-vault-ftp-server with the same operation within the MuleSoft AWS S3 connector.
Similarly, you can Create Document Renditions on Vault through Mule File (create-document-renditions-using-metadata-from-file.xml) contains below flows respectively:
- create-document-renditions-synchronously-using-csv-metadata
- preload-renditions-on-vault-ftp-server
- independant-upload-rendition-files-on-vault-ftp-server.
Note - This sample creates document records (Bulk API) synchronously in batches of (500) records. If the create document records (Bulk API) is invoked asynchronously (i.e invoking multiple Create APIs simultaneously) will impact vault performance and is therefore not recommended by Veeva.
**2. create-object-records-using-metadata-from-file.xml :–
The flow (create-object-records-synchronously-using-csv-metadata) create object records for an object “Study Site**”. It reads metadata from a CSV file and passing records in batches of 500 records to for-each loop which creates object records using Bulk API. The status of the object records created are recorded in a file on the local file system through Write operation.
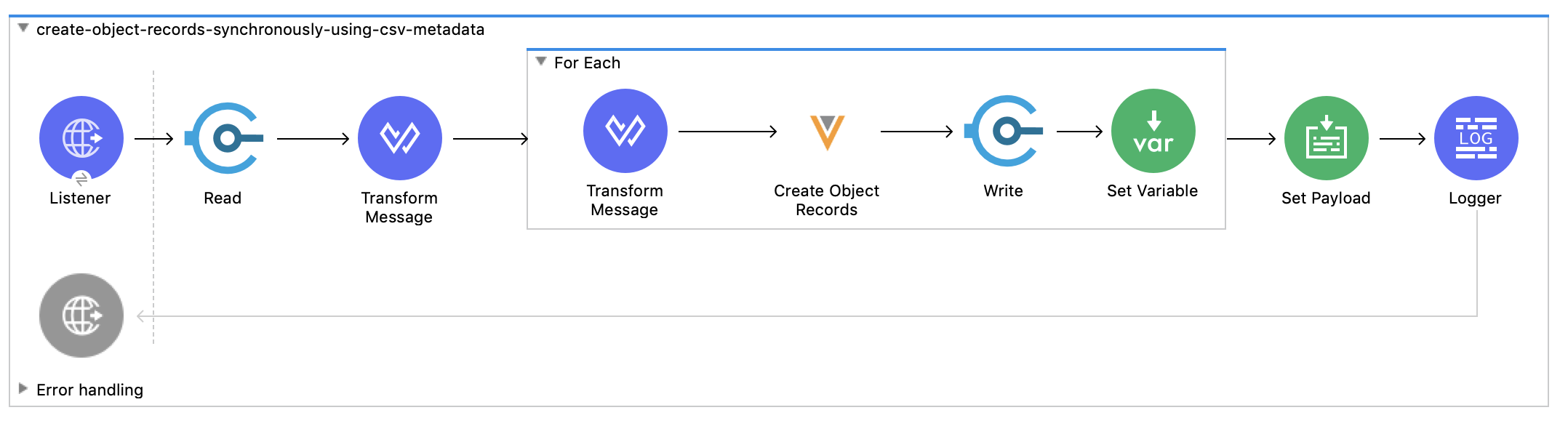
Note - This sample creates object records (Bulk API) synchronously in batches of (100 – 500) records. If the create object records (Bulk API) is invoked asynchronously (i.e invoking multiple create object records simultaneously) it will impact vault performance and is therefore not recommended by Veeva.
Use Case
As a Vault user I would like to
- Create Documents in Vault by reading metadata from a local CSV file and uploading the corresponding document files to Vault FTP server to associate the respectives file with documents created. This should occur in two steps:
- First, upload documents files from local file system to Vault FTP server in batch wise (500).
- Create Documents on Vault in batch (500) using pre-loaded document files on Vault FTP server.
- Create Object records in Vault for the Vault Object (Study Site) by reading object metadata from a local CSV file.
The above use cases can be used for Migration and Process Integration.
- For Migration use case: This use case where large number of documents/objects to be migrated from third party system to Vault. In this case first, high volume of document files that need to be migrated are uploaded through independent flow (independent-upload-files-on-vault-ftp-server) before creating documents on vault. This is applicable to both Document and Document Renditions creation.
- For Process Integration: This use case where small number of documents to be updated/migrated from Veeva Vault to third party system and vice-versa. In this case, the document/renditions files are uploaded in batch prior to creating documents/renditions on vault.
In these examples documents and objects in Vault are created from metadata and files (local file system). Should you wish to integrate with a third party vendors product, these steps in flow can be replaced with the required vendors operations. For example, in the case of the create-documents-synchronously-using-csv-metadata flow, rather than obtaining the document metadata to a within the Read operation the data can be obtained for the appropriate third party connector’s read operation instead.
This template serves as a foundation for creating documents and object records in vault using metadata read from a local file and uploading corresponding document files from the local system. Document and object metadata from third party products can also be integrated to create documents and objects based on your requirement.
This template can also be used as a starting point to adapt your integration to your requirements.