Veeva Vault to File System | Implementation Template
home
This template contains the following mule application files:
- retrieve-documents-from-vault.xml :–
The template contains flows to retrieve vault document records and their metadata (retrieve-documents-detail),export the documents files or document renditions to the Vault FTP staging server (export-documents-from-vault) and download the exported files to local file system through flow (files-download-from-vault-ftp).
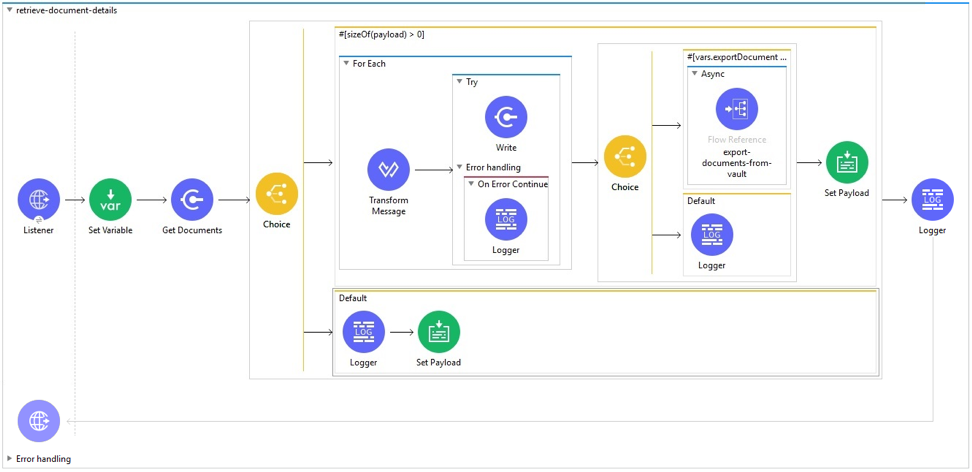
In this retrieve-documents-detail example, the exporting the Documents and/or Document Renditions is controlled by passing a query parameter of either ExportDocument=True or ExportDocument=False to the Listener call. This is then converted to a variable called exportDocument in the Set Variable operation which is used later in the flow.
Details of the documents are retrieved using the pagination and streaming mechanism, as documented in the Veeva Vault User guide under Pagination and Streaming section. In this example this is done using Get Documents to retrieve the documents in batches, and the subsequent For Each loop to handle the processing per document metadata. The documents metadata details are recorded in a file using the Write operation.
If the exportDocument variable was previously set to true, exporting Documents and Document Renditions files happens asynchronously in batches of 100 documents per Job, by calling the subflow export-documents-from-vault.
export-documents-from-vault :-
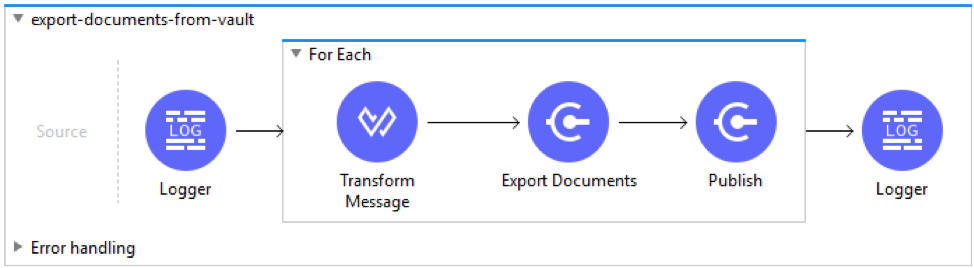
The Export Documents operation creates a job that exports document/renditions files on Vault FTP Staging area. The types of document files exported are controlled within the Export Documents operation, as follows:
Exporting Document Files: The flag Source File in the operation Export Documents controls whether document file attachments are exported. By default this flag is set to “true”, however if only metadata is required with no document file(s) export pass the flag “ExportDocument=false” instead.Exporting Document Renditions: The flag Renditionsin the operation Export Documentscontrols whether document rendition files are exported. By default this parameter is set to “false”, however if renditions are required this should be set to “true”. To export only renditions in a single call the flag Source File should be set to “true” otherwise set to “false”.
The Document and Renditions files are downloaded from the folders created through Export Documents operation on Vault FTP Staging area under system userId (User credentials configured in connector configuration) directory and subdirectories location (Eg. /uXXXXXXX/)
After the job is created, this operation then polls vault to retrieve Job Status until it completed successfully at intervals of (30 seconds). On SUCCESS, it retrieves Job results which is published on the VM queue (using the VM Connector - Publish operation) and is then subsequently processed using the flow - files-download-from-vault-ftp.
Files-download-from-vault-ftp :-
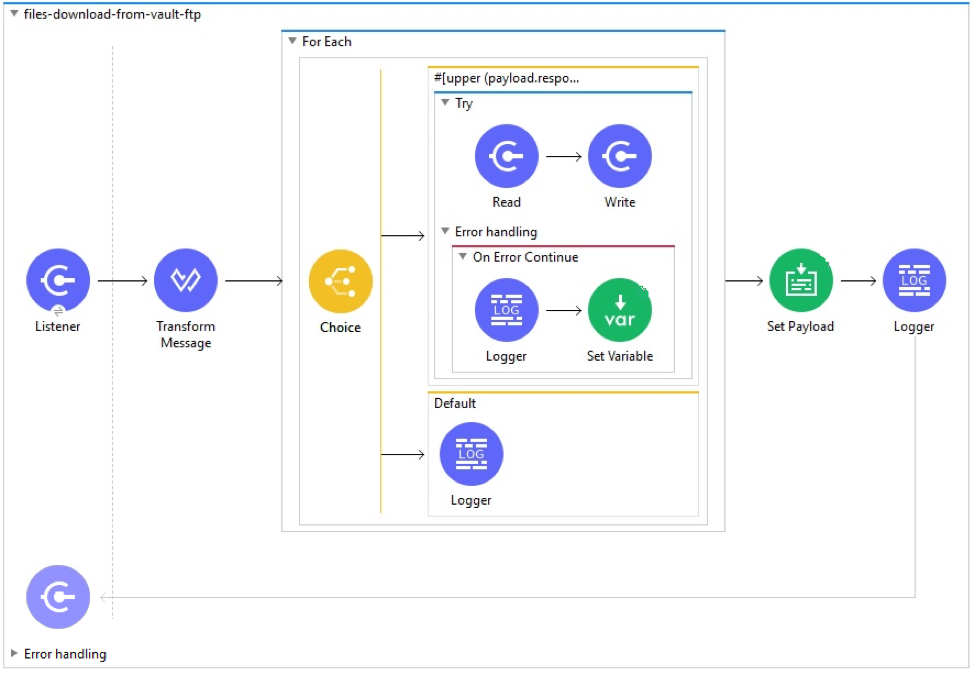
The VM Listener (files-download-from-vault-ftp) listens on the VM queue. When a queue entry is received and transformed, it then loops through each of the document/renditions records contains userid and file path. Using userId and file path it reads the file on the Vault FTP Staging server and writes them into the corresponding absolute location on a local file system. It’s worth noting that this use case will only work when deployed in an on-premises environment and not within instead on CloudHub.
Should you wish to download document files to a different location/environment than a local file system. For instance, if you wanted to use an on cloud file store such as AWS S3, you can configure a MuleSoft AWS S3 connector in try block to upload file content to an S3 bucket in place of the Write operation within the flow files-download-from-vault-ftp.
Note: The sample version of the flow files-download-from-vault-ftp downloads files across 4 threads simultaneously. This is controlled within the Max Concurrency setting within the flows Flow Configuration which in turn uses the configuration value ${flow.max.concurrency} is specified in the projects configuration file src/main/resources/config/configuration.yaml. In order not to overload the connections to the Vault Staging server this value must not be set greater than 5.
2. retrieve-document-renditions-from-vault.xml: -
This template is similar to “retrieve-documents-from-valut.xml”, the only difference is Renditions flag in Export operation (flow – export-document-renditions-from-vault) is set as “true” to export renditions along with document files.
3. retrieve-object-records-from-vault.xml: –
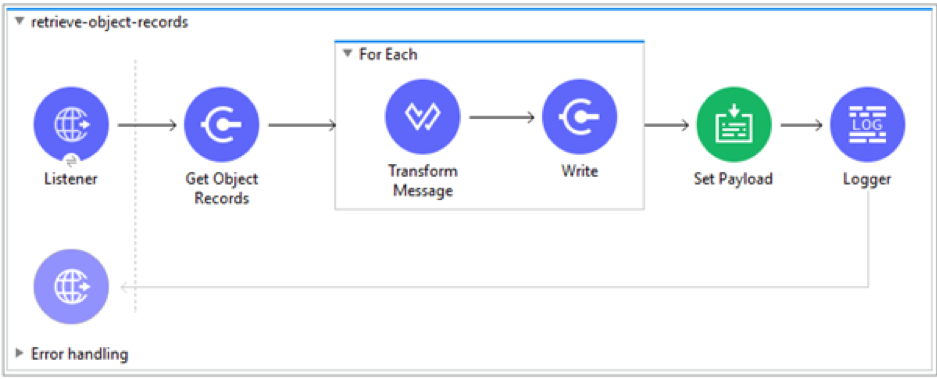
The template contains the flow (retrieve-object-records) that retrieves Vault Object records and writes them to local file system using the Write operation.
The Object records are retrieved using the pagination and streaming mechanism, as documented in the Veeva Vault User guide under Pagination and Streaming section.
Use Case
As a Vault user I would like to:
- Retrieve Documents records and their metadata from Vault and also export the associated documents files or document renditions to the local file system. The export of the documents files or document renditions, should occurs in two phases:
- First the documents files or document renditions will be extracted to the Vault FTP Staging server.
- Once step 1 is complete, a separate flow downloads the document files from the FTP Staging Server to the local file system. Depending on the volume and size of the files being downloaded, this step can take some time.
- Retrieve Vault Object records and metadata from specified Vault Object and save the object records in a JSON file on the local file system.
The above use cases can be used for both Process and Migration Integrations.
- For Migration Integrations:- This is applicable where large numbers of Documents/Objects need to be migrated from a Vault to either another Vault or to a third party system.
- For Process Integration:- This use case where small number of documents to be updated/migrated from Veeva Vault to third party system, often as part as a scheduled transfer of data.
This template serves as foundation for retrieving document and object details from vault and can also be used to integrate to other vendor products. In these examples metadata and files are written to a local file system. Should you wish to integrate with a third-party vendors product, these steps in flow can be replaced with the required vendors operations. For example, in the case of the retrieve-documents-detail flow rather than writing the document metadata to a within the Write operation within For-Each loop, the metadata can be transformed and written to other vendor products using the appropriate third party connector instead.
This template can also be used as a starting point to adapt your integration to your requirements.