Salesforce to Apromore Template
home
About Apromore
Apromore is a process mining company built by the people at the forefront of process mining research. Our software has been used by organizations around the world to achieve digital transparency and leverage the full potential of their transactional data. We’ve worked with leading companies in the banking, insurance, healthcare, manufacturing, education, engineering, utilities, and government sectors. We’ve helped to enhance their productivity, product, and service quality, and compliance, as well as generate huge returns on investment.
About the Template
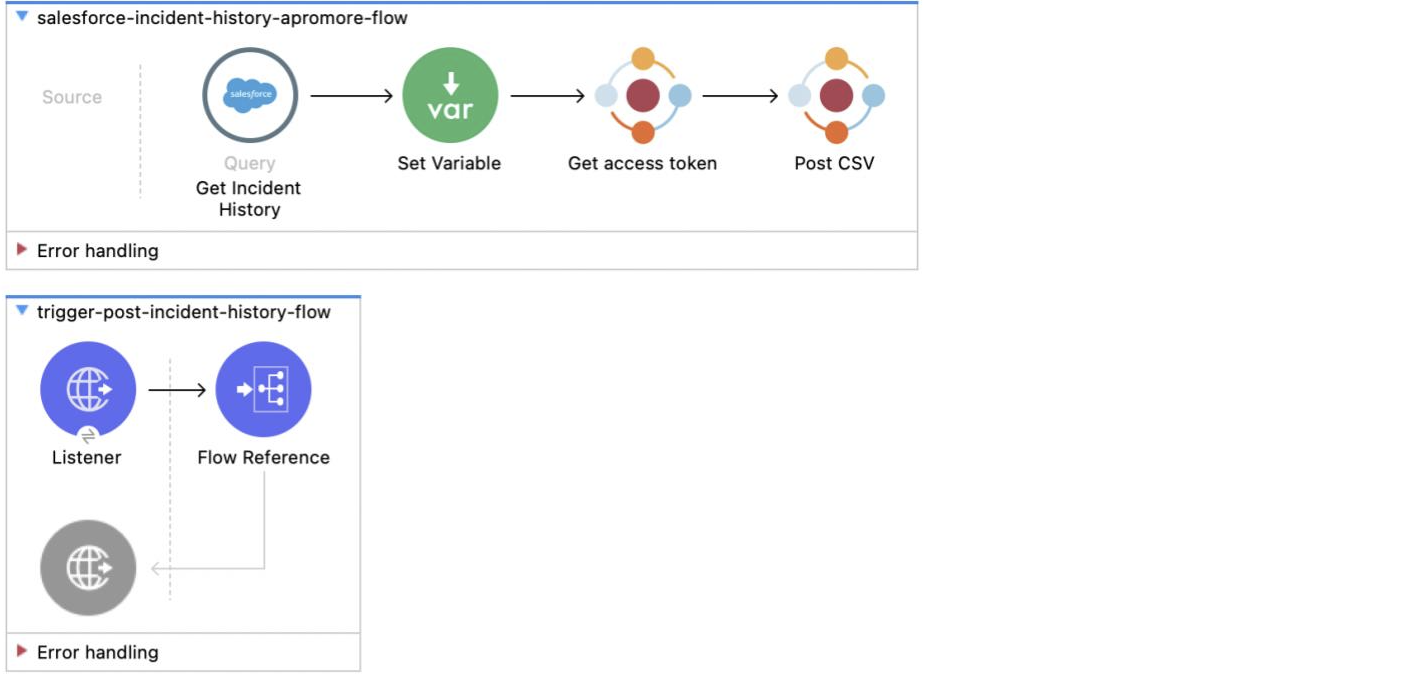
The template shows how the incident management history can be fetched from Service Cloud and ingested into Apromore via the connector.
How it works
The integration flow is triggered by an HTTP call that can be used manually or programmatically. Changes in Incident status are collected from Salesforce using a SOQL query and a CSV file is created containing data from both the Incident History and Incident table. The column types are then tagged and the CSV file is ingested into Apromore as an event log.
Note that to collect Incident status changes, field history tracking must be enabled for the Incident status field in Salesforce.
Data flow
What you need
- A Salesforce account
- An Apromore account with the integrator role
How to use it
- Import the template
- In the properties file:
- Enter credentials of your Salesforce account
- Enter credentials of your Apromore account
- Enter additional details of the IAM used for the Apromore application
How to use it for different objects
- Modify the Salesforce query to fetch data from other tables in Salesforce
- Modify the CSV conversion such that it creates a valid CSV from the query result
- Modify the Log Metadata field in the Post CSV operation so that all columns in the CSV are tagged and pushed to Apromore
Use Cases
Analyze ServiceCloud incident management history in Apromore in order to :
- measure service-level quality, e.g. by identifying incidents that have not met the SLAs
- assess customer experience, e.g. by identifying rework, bottlenecks, and other frictions in the management of incidents that affect customer experience negatively
- measure resource performance, e.g. by identifying high-performing teams vs low-performing ones
- identify anomalies and other compliance issues, such as incidents that have ended abruptly or incidents that have workarounds to skip specific states.
The implementation begins with fetching the incident history from Salesforce Service Cloud and transforming it into a CSV file. The CSV file along with the tagging information is ingested into Apromore as an event log via the connector.
Considerations to make this template run, the following preconditions must be met.
Salesforce
- You must have a Salesforce account with Asynchronous API enabled.
- As this example looks at the changes in Incident status, it requires field history tracking to be enabled for the Incident status field. This will keep a record of all the changes to the Incident status field.
Apromore
You must have an account in Apromore with the Integrator role.
Run it!
Running On-Premise
Add all the properties in one of the property files (e.g. local.secure.properties) and run your app with the corresponding environment variable. To follow the example, use env 3D local.
After this, simply trigger the use case by sending a request to the URL specified by the HTTP listener. In this example, the request should be sent to http://localhost:8081/upload/incidentHistory.
You should receive a response that looks something like this:
{
"folder": null,
"name": "incidentManagementData",
"id": 123,
"calendarId": 0,
"domain": "",
"ranking": "",
"makePublic": null,
"owner": "your_username",
"hasRead": true,
"hasWrite": true,
"hasOwnership": true,
"createDate": "2022-06-17T15:19:24.754+10:00",
"ownerName": "your_username"
}Login to Apromore and check that the "incidentManagementData" event log has been added to your Home folder.
Running on CloudHub
Deploy the application to CloudHub and add your properties and environment variables. Note that sensitive information, such as passwords should be secured. See https://developer.mulesoft.com/tutorials-and-howtos/getting-started/how-to-secure-properties-before-deployment/ for more information.
Salesforce login details
- salesforce.username - Your salesforce username
- salesforce.password - Your salesforce password
- salesforce.token - You can reset and obtain your security token using this link.
- salesforce.authURL -
https://login.salesforce.com/services/Soap/u/53.0
Apromore login
- apromore.baseURI - The base URI of your Apromore application (eg https://test.apromore.org)
- keycloak.realm - The name of the keycloak realm used in your Apromore application
- keycloak.secret - The client secret of your keycloak realm
- apromore.username - Your username in Apromore
- apromore.password - Your password in Apromore
Customise it!The template can be used to push any event log from Salesforce to Apromore. Simply replace the query, update the CSV transformation step to create a valid CSV from the query, and match the Log Metadata in "Post CSV" operation with the columns of the CSV.
Updating the query
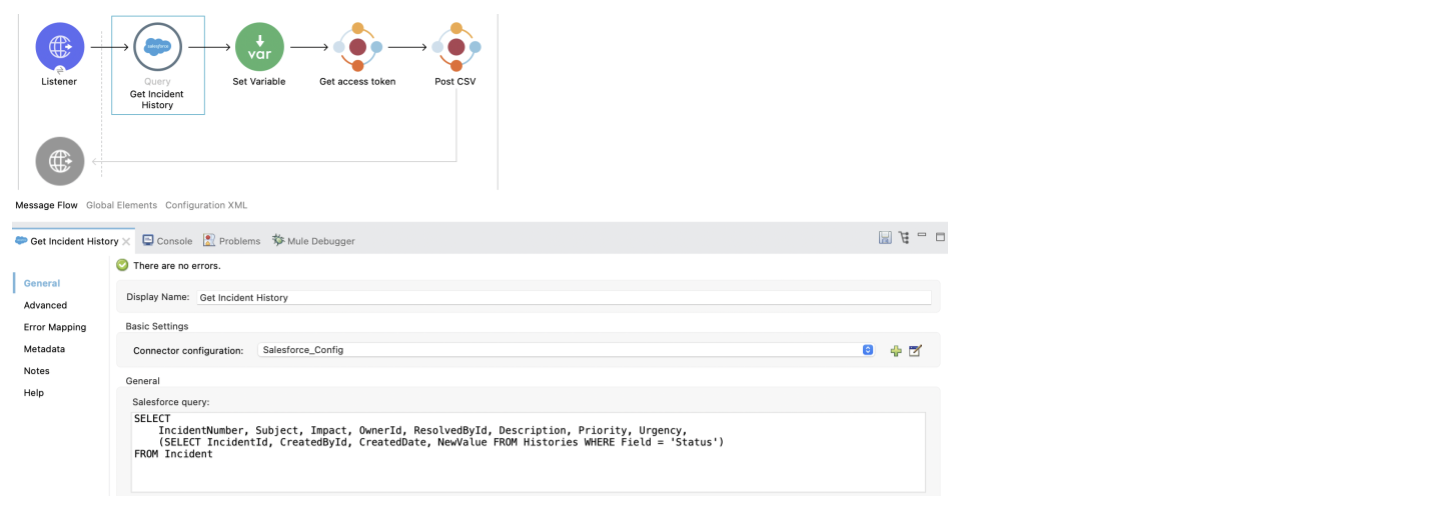
The query is used to fetch selected columns from the Incident and Incident History tables. It is written using Salesforce Object Query Language(SOQL) and can easily be modified to fetch other columns or tables from Salesforce that can be converted into an event log.
Updating the Transformation
The transformation is performed using a DataWeave script.

If we are only fetching data from a single table, then the transformation is simple, we just need to convert the JSON to CSV as shown below:
However, the JSON object returned by the query may not easily be converted into CSV. In such a case, we need to transform the JSON into an array of objects containing fields with simple values (no object or array values) as seen in the script below.
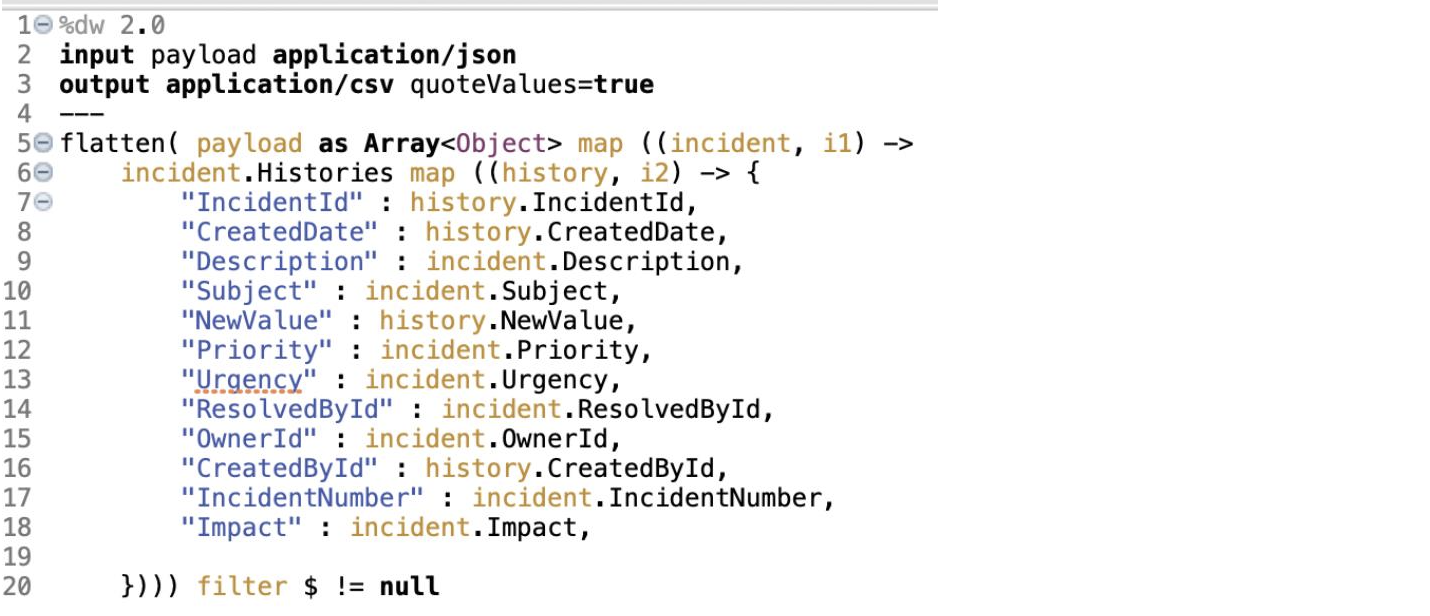
Updating the Log Metadata
The Log Metadata field is used to define the column types of the CSV created in the transform step. The different attribute types like case id, activity, and end timestamp are mandatory to perform process mining using Apromore. Additional attribute types like resource, role, perspective, case/event attribute can be specified to perform further analysis in Apromore.
The column types are specified as a stringified JSON with the following format:
[
{
"name":"id",
"attribute_type":"case_id",
"data_type":"string"
},
{
"name":"activity",
"attribute_type":"activity",
"data_type":"string"
},
{
"name":"date",
"attribute_type":"end_timestamp",
"data_type":"date",
"date_format":"yyyy-MM-dd"
}
]Requirements/Restrictions
- All columns in the log must have an attribute_type and data_type specified
- All columns with data_type 3D date must also have a date_format specified
- A case_id, activity and end_timestamp field are required
| Attribute Types | Number of Columns | Valid data types |
|---|---|---|
| case_id* | 1 | String |
| activity* | 1 | String |
| start_timestamp | 0-1 | date |
| end_timestamp* | 0-1 | date |
| resource | 0-1 | String |
| role | 1 | String |
| case_attribute | 0-1 | string, date, integer, float |
| event_attribute | ANY | string, date, integer, float |
| perspective | ANY | string, date, integer, float |
| ignored_attribute | ANY | string, date, integer, float |
*Marks a required field